Fixing OneDrive annoyance with Rstudio on Windows
By default, Rstudio on Windows with OneDrive installed stores packages in the OneDrive documents folder. This package location causes a lot of issues:
- It causes a lot of upload to OneDrive
- It can cause conflicts between machines (since they will be storing to the same OneDrive folder)
- It can cause unnecessary delays in having to download files from OneDrive (if they are not locally cached)
All in all, this location seems to be a poor side-effect of making OneDrive the default storage location on Windows. It can be easily rectified. Simply create a file called .Renvironment in “C:\Users\<username>\OneDrive\Documents” (AKA your OneDrive documents folder) with the following line:
R_USER="C:/User/<username>"
This one line redefines the user-specific directory to be on the local disk, in C:\Users\<username>. This is the exact same place as the %USERPROFILE% environment variable on Windows. The site-wide .Rprofile will make use of this variable and create an package path using it as a base.
These mechanisms are explained here, and it is simpler than editing the site-wide .Rprofile as described here (and many other places), which would require you to repeat the procedure on new installations (and also requires modifying files in the base installation path).
Causation, Correlation, and Instrumentation
One confounding problem in statistics (and life) is distinguishing causation and correlation. Let’s say we can observe two things simultaneously: X and Y. We collect many such observations. We notice that X and Y always move together. When X goes up, Y goes up (and vice versa). When Y goes down, X goes down (and vice versa). We would like to say that X causes Y. That is, we would like to draw a graph as follows, where the arrow indicate the direction of impact: X causes Y.

However, we can’t make that statement (at least not based on these observations) for a few different reasons.
Reverse Causation
The first is that we only know X and Y move together. It could be that Y in fact causes X. An example would be an alien observing human behavior. The alien notices that days that humans have umbrellas tend to be rainy days. The alien concludes that umbrellas cause rain. Instead of the model of X causing Y, our model is that Y causes X:

Fundamentally, the problem here is Y and X are just things we can observe. We don’t really know which is Y and which is X. Does social media cause anxiety/depression, or are depressed/anxious people more likely to go on social media?
Hidden Variable
It could also be the case that X and Y both depend on another variable V that we can’t see. Here is an example:
Do churches cause murder? In the 1980s several studies used census data to show that the more churches a city has, the more murders occur in the city each year. With tongue in cheek, the authors claimed to have proved that the presence of churches increases the prevalence of murders. While the data were correct, the conclusion was obviously nonsense. What is the hidden variable here? Larger cities tend to have more of everything, including both churches and murders, so the hidden variable is population size.
Stuart Math – Discovery Project: Causation and Correlation
We have the model below:

In this case, X does not cause Y. And Y does not cause X. V causes both of them. What’s worse, we can never be sure that one or more such variables exist.
Overall Confounding Model
Putting it all together, we get a model where we can only observe X & Y. X can cause Y and/or Y can cause X (possibly simultaneously). In addition, both X and Y could depend on another variable which we cannot see.
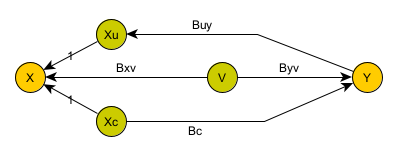
To make things clear, I split out X into two terms: Xc (which does cause Y) and Xu (which is caused by Y). We do not have access to Xu and Xc: they both contribute to X (which we can observe). (In fact, they really don’t exist: they are just a convenient way of splitting X up into two contributors.)
By definition, the hidden variable V is a root cause: it does not depend on anything else,
but both observations (X & Y) depend on it.
What we are after is the term Bc: that tells us what portion of Y depends on X.
Instrumentation
To do so, we are basically going to cheat: we are going to try to find another variable Z which we can observe.
This variable needs to be unrelated to Y. That is, there can be no direct relationship between Y and Z. Other than through X (Xc in this model), Y and Z cannot have any dependencies on each other. In fact, we cannot just judge this by looking at statistics. We need a non-statistical reason for this to be the case.
Our model now looks as follows:
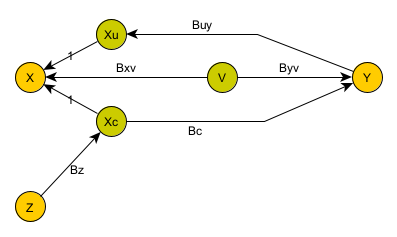
The key here is that we have found a miracle variable Z. We know (through some other argument) that Y does not depend on Z.
What if (hypothetically) V depends on Z? Well, it can’t. By definition, a hidden variable cannot depend on another observable variable in the system.
By correlating/regressing X to Z, we can get Bz. Then, by correlating Y to X (or really an estimate of X synthesized from Z), we can get Bc.
Motivation
I really wanted to just draw the diagrams of all these different effects without introducing math. I came across all these ideas in a statistics class last week, and I could not keep an understanding in my mind without a picture. Once I had the pictures, I felt the concepts were much easier to understand.
Asking the Wrong Questions

One question I like to answer myself essentially poses itself is the personal investment question: if I had some extra time, money, wishes, etc. Would I put them into making the best hours of my week better? Or would I put them into making the worst hours of my week better?
For example, should I buy a new coffee maker, so that my morning coffee on my way to work is better? Should I buy new headphones so that I can listen to music in bliss while I work?
Or should I put that money into an attachment for my bike, so that when I go for a bike ride, I can capture video of it. Or should I instead buy tickets to a fun concert for me to attend on the weekend?
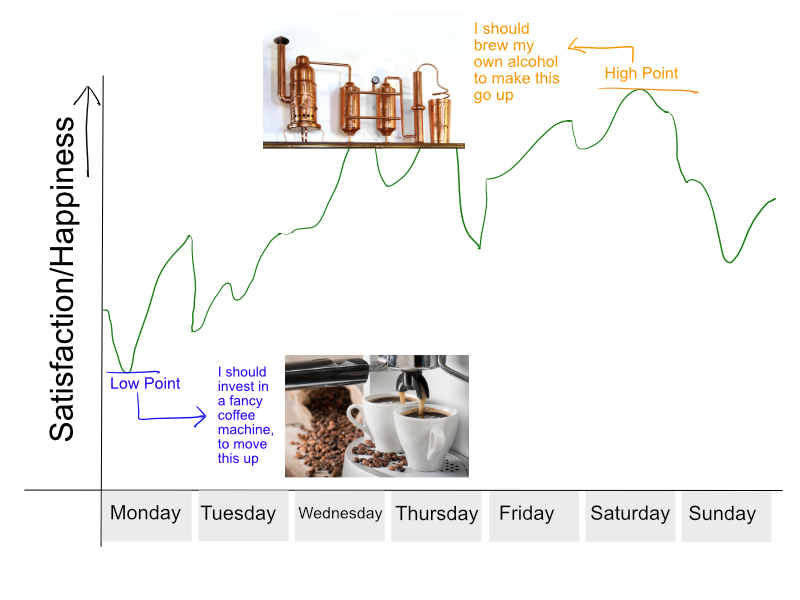
Knowing this goal is somewhat useful knowledge. For example, if I’m already energized at work maybe the coffee doesn’t make sense, or if I look forward to interacting with my workmates, maybe the headphones don’t make sense.
Alternatively, if I’m constantly worried about work, the concert could either be a great distraction, or it could be pointless if I’m going to obsess about the work I have to do anyway.
Thing is, this question of optimization is pretty limited. And, in fact, it might actually be in the way of my happiness.
There is another alternative: maybe neither the best hour of my nor the worst hour of my week need fixing. I posit that viewing life itself as an optimization problem is a problem itself. (Well, maybe not a problem, but certainly a short-sighted distraction.)
This constant need to improve ones’ life is itself an incessant treadmill. You’re constantly looking for the best deal on what you need next. Or you feel like you don’t have enough time to do the project you set out to do that will make life (the best or worse moments) better.
Instead of buying better headphones, enjoy the ones you have.
I’d place this seemingly logical question in a class of questions which seem like they are useful, but are really an artificial mental construction which doesn’t necessarily have any grounding in reality. But, since we thought the thought, it’s hard to admit (or understand) that the question itself can be dismissed, that it was conceived in our mind, and isn’t indeed part of the world around us. Usually, “Why did so-and-so do that?” fall into this category: trying (or pretending to try) to explain someone else’s behavior when we have our own mental model.
Finally, optimizing on a week-by-week basis is also arbitrary. Maybe the best thing you can do is to forego any change for months, so you can incrementally get to a better point in a year. (I picked a week here, because most people have 5 work days and 2 weekends, so you see the contrast between the best and worst times during the course of a week.) Things that have made me truly happy usually took longer than a week.
Mesh WiFi Recommendations
Mid-2020 Recommendation
So if you are in the market for a mesh WiFi solution, which one should you get? It depends on whom you trust.
WireCutter rated Eero the best. But Eero is owned by Amazon, so consider whether you trust Amazon. Synology also has a good name with tech enthusiasts; and it has a good upgrade path. WireCutter considers it their 2nd best WiFi router (outside of mesh), and you can add up to 6 mesh devices later; that said, WireCutter says the setup is more complicated than Eero.
If it were me, I would probably go with Synology. They are well-known in other network device markets. They also have a good track record of updating their routers (for security, etc). While the setup may be more complicated, I like that you can add more devices in the future.
I have seen many other tech-enthusiasts go with Google/Nest WiFi. (I bought my WiFi equipment from someone who was selling it because he bought the Google WiFi solution.) But Google has a history of dropping products, and I worry that WiFi could be next. Finally, WireCutter said it was behind Eero in performance.
Gory details and discussion follows.
Read the rest of this entry »My Password Setup
So, I’m basically making this post so I can share with friends/family. In this post, I will explain what I do for managing passwords, including two-factor authentication (2FA), and give some options for getting 2FA. Before I do that, I will explain how I got to the conclusion on what I am using.
For those that don’t know me, I am not a security expert. You should do your own research (and maybe consult the security experts out there). I could be wrong about some of my conclusions. And more generally, what might work for me might not work for you.
Also, the scope of what I explaining here is only for my personal accounts. My company (and most out there) has an IT policy for work accounts.
You can skip past the Intro, if you don’t need convincing on why reusing passwords is insecure. Also, I put my recommendations right up-front in the Bottom Line section, if you don’t want to read the whole article.
Read the rest of this entry »A Morning in Fond du Lac
I woke up on Saturday morning in Fond du Lac, Wisconsin. I took some pictures.




Orion

My first foray into astrophotography—if you can call it that. I took two pictures at two different exposure lengths and then merged them.
VOIP Cost Calculations
So, in August we made a total of 1755 seconds of outgoing calls from our landline.
I currently use voip.ms to make these outgoing calls. Their rate (using premium routing) is 1 cent per minute. (Curiously slightly higher for toll-free calls.) Anyway, I paid a whopping 30.7 cents for all these outgoing calls in August.
Right now, I still have AT&T handling incoming calls. If I were to cancel AT&T, I would save roughly $20 per month.
Instead, I would have to pay for incoming calls as well. As well as 911 (E911) service. Both voip.ms and CallCentric (a service which seems to be mentioned a lot online) provide E911.
With CallCentric, their North America Basic plan includes E911 and 120 minutes of outgoing calls; this costs $1.95 per month. (After 120 minutes, which I probably won’t use, it’s roughly 2 cents a call.) In addition, I can pay $1.95 monthly plus 1.5 cents per minute to receive calls. (I could also pay $5.95 for unlimited outgoing calls, but given how few calls we take, that does not make much sense.)
With CallCentric, the costs would come out to $1.95/month + $1.95/month + 1.5 cents/minute-incoming. So, $3.80/month + incoming 1.5c/minute.
With voip.ms, as I said before, they charge per-minute on outgoing calls. (This is why I picked them in the first place: no monthly fees, and very cheap usage rates.) For incoming calls, the rate is $0.85/month plus 0.9c/minute. For E911, I pay another $1.50/month. So, I’d pay $2.35/month + 1c/minute-outgoing + 0.9c/minute-incoming. (voip.ms also has a $4.25/month unlimited incoming call plan. However, it isn’t clear to me whether this includes E911.)
So, all of this depends on how many incoming calls I receive on average. (Unfortunately, AT&T does not list this on the bill, since it’s basically free—er, included with my monthly service.) I can’t imagine it amounts to more than a few hours per month. And to be honest, the differential between CallCentric and voip.ms is so low, I don’t know that it matters (roughly a buck or two in the end).
Shipping Options while eBaying Electronics
I’ve been spending some time e-baying electronics lately. (Just trying to get rid of old, unused stuff that never panned out.)
Because, I visit this topic so many times (every time I eBay), I thought I’d put some conclusions for myself on how to ship these.
I really like the priority options from the USPS. There are two options here: flat-rate or regional rate.
First, this chart lists whether it’s better to do regional rate or flat-rate. The important thing to remember is that it’s heavily dependent on the size of the item you are shipping.
If it can fit, the small flat-rate box is preferred. It is $6.65 at the Post Office or $5.95 “commercial base” (which I think means online).
The only issue is that the small envelope is the inside of these boxes are 8 5/8″ x 5 3/8″ x 1 5/8″. This should be big enough for a 3.5″ internal hard disk drive (which measures 5.75″ x 4″ x 1″).
But it’s probably not big enough for anything else (routers, external hard drives, etc.). Instead, for a flat-rate option, you’d have to go with the Medium Flat Rate Box – 1 (top loading). This costs $13.60 at the post office or $12.40 “commercial base”.
Instead, if you have something this big, it probably makes more sense to go with the regional rate box A1. These are 10 1/8″ x 7 1/8″ x 5″. This goes by zones (difference between starting and ending zone). As long as you are within 8 zones, it makes sense to go with these. If you are within one or two zones, it is as cheap as $6.52. (Curiously, this price list is hard to come by on the USPS website. Instead, I’m linking to stamps.com.)
Finally, for 2.5″ SSDs, you can probably get away with a padded envelope (or small flat-rate box). The prices are around the same, but there’s a lot less packaging/padding to add with the envelope.
My plane ride back from San Diego
I’ve always held that you can’t judge people by appearance. I also lament the dearth of women in engineering (and STEM in general). Here’s a little anecdote:
On a recent flight back from San Diego (for work), I sat next to two young women.
As people boarded, I overheard snippets of banter from the two women about plans for the weekend and possibly a popular musician.
I started a conversation the way I start every conversation on a plane: “How are you today?” And the young lady closer to me smiled and said she’s doing great. I asked if they were going home, and she said they were on business.
I asked what it is that she does. We talked for a while, and I learned that they work for Abbott Labs. They are in a rotation plan that lasts 2 years, and each rotation lasts 6 months. She had done a few rotations, and one of them was in Chicago. They are both currently assigned to a location 45 minutes away from San Diego.
What struck me here is that this is how things used to be at Motorola (well, sort of—a better example is Intel). I was happy to hear of a company that still invests so much into young talent. That it’s a Chicago company was a nice bonus.
I asked what they do for Abbott, and they are both engineers. I asked if this was chemical and they said biomedical. Abbott basically spun off their pharma business as AbbVie and retained medical devices.
As we took off and I looked along the coast, I asked whether they worked north or south of San Diego. The young lady closer to me said north, ’cause 45 minutes south would be Mexico. I smiled at my obvious error.
For most of the flight, I put my headphones on as they talked amongst themselves. They were clearly traveling together, and I didn’t want to be an interloper.
Closer to Chicago, I heard them talk about restaurants. I asked if they wanted a recommendation. The young lady closer to me reminded me that she had lived in Chicago and she knows the area. I took this rebuke to mean that they prefer to converse amongst themselves, and so I went back to reading the WSJ that I grabbed from the hotel. (I tend to be on the chattier end of things and have to watch it—especially with strangers.) I smiled and suggested that maybe she should give me a recommendation, seeing as how I don’t get out much.
Finally, near the end of the flight (when they were both quiet and seemingly bored), I asked where they went to school. They had both gone to Cal-Poly (the good one ’cause there are apparently two). I asked where they want to be when they’ve finished the rotation program. They both wanted to move to the Bay area when their rotations were over. The young lady closer to me reminded me that she was almost done with the rotation program.
They both agreed that Northern California was Better. (I said how Northern California is nice because it is cooler and that’s good for running.) The young lady farther from me talked about how in Northern California, they say “Hella”. Like, “Hella-fun day.” But they don’t say that in Southern California.
At the end of the flight, I told them it was nice to meet them and I hope they have a good time this week in Chicago. I said, “Would that be a hella-good time?” They young lady farther from me laughed and said that I got it. The young lady closer to me smiled and said that I don’t have to say “hella”; she’s from Northern California and she doesn’t.
So, here’s why I’m bothering to write about this particular conversation: I was absolutely delighted that the young lady closer to me acted like almost every other engineer I have met—correcting factual mistakes when dealing with people. Because if you don’t correct people, they will veer off in the wrong direction. And Bad Things will happen.
It made me feel glad that I had evidence for something I’ve long held—that there’s no inherent difference between men and women. And you can’t judge people by the way they look. And you can only know someone by interacting with him/her.
And at some point in the past, these young ladies would have been encouraged to be pharma reps, not engineers. (I do not suggest that being an engineer is necessarily better than being in sales—I do suggest that reducing bias and allowing individuals to choose their own career options is better.)
Well done, Universe.